-
B-NET Home Bioinformatics
Software Datasets Projects
NexGen Sequencing
Useful Links
Odds N Ends
Basic Information (expanded)
DNA File Types
DNA Trace Files: Also called a chromatogram, a DNA trace file holds the data from a dideoxy sequencing experiment. Trace files usual end in a *.abi, *.ab1, *.scf
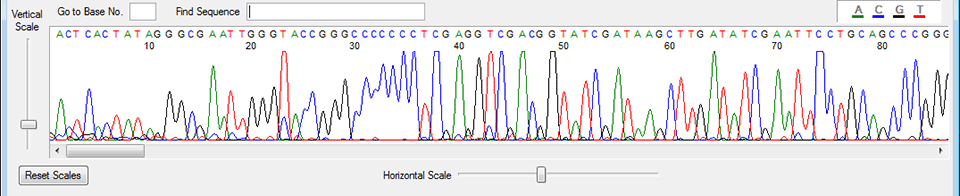 The chromatogram or DNA trace is not editable. However, the file hold more information than this image. The DNA sequence at the top of the trace has been deduced from the peaks by the original sequencing computer. Deriving the DNA sequence from a trace is known as calling. There are other programs, such as Phred, that will take a trace and call or derive a DNA sequence based on parameters you can set. The DNA sequence called by the program is contained within the trace file as well as information on the sequencing run. This information can be extracted from the trace. Here is a compressed (zip) trace file for the image above.
Example DNA sequence as a trace file
The chromatogram or DNA trace is not editable. However, the file hold more information than this image. The DNA sequence at the top of the trace has been deduced from the peaks by the original sequencing computer. Deriving the DNA sequence from a trace is known as calling. There are other programs, such as Phred, that will take a trace and call or derive a DNA sequence based on parameters you can set. The DNA sequence called by the program is contained within the trace file as well as information on the sequencing run. This information can be extracted from the trace. Here is a compressed (zip) trace file for the image above.
Example DNA sequence as a trace file
DNA File Types: DNA sequences can be contained in many different file types. The more complex would be a trace file, described above. The simplest, and most common, is a text file. DNA, as well as RNA and protein (amino acid) data can easily be described by letters. Most DNA sequence files are text files. At the simplest, there is just DNA sequence. The more complex text files contain comments and other data.
Text File: (*.txt) The simplest type of DNA file, containing only DNA sequence as IUPAC letters; no numbers or symbols. This type of file can be edited by Notepad (or Notepad++) or other word processing programs. Make sure to save as a TXT file to avoid inclusion of other style tags. Example DNA sequence as a text file
Fasta File: (*.fa, *.fst, *.fsa) This is a straight text file and is one of the most common file types used in Bioinformatics. The first line of the file usually begins with a greater than sign (>). Any text between this symbol and a hard return is considered description and will not be included in the sequence. The DNA sequence is typed after the hard return. Multiple DNA sequences can be contained in a Fasta file; each new sequence begins with a greater than sign (>). RNA and amino acid sequences may also be contained in fasta files. Example DNA sequence as a fasta file
GenBank File: (*.gb, *.gbk, *.gen, *.gnk) This may also be called a GenBank flatfile. This is a straight text file that contains a lot of data in addition to the DNA sequence. It's the native file format for GenBank and other databases. The accession number (a unique identifier), is part of this additional information, as well as source information, translated open reading frames, associated references and more. Example DNA sequence as a GenBank file
EMBL File: This is another text file with a header containing non-sequencing information, followed by the sequence. It is European Molecular Biology Laboratory (a major database) format.
Sequence Alignment Files: (*.fa,*.msf, *.phy, *paup, *.mas, *.aln) This is a data file containing multiple sequences that are about to or have been aligned by a sequence alignment program such as Clustall, Seaview or FASTP. No matter which file type you are dealing with, the format and syntax must be correct. Alignment programs as well as phylogenetic programs that use the alignment data are very touchy about format and syntax. BioEdit is a good program for viewing, aligning and exporting multiple sequences. That's what it was designed for. Different file types are interleaved, the sequences are shown in aligned blocks, or non-interleaved, each sequence is shown seperately. Genbank format is non-interleaved, while msf is an interleaved format.
Some common file types and extensions: BioEdit (*.bio), FASTA or FASTP file (*.fa, *.fst, *.fsa), Nexus file (*.paup), IG/Stanford (*.ig or *.sn), Fitch file (*.fch), MEGA (*.mas) Clustal (*.aln), Wisconsin Package multiple sequence file (*.msf),
Example of an non-interleaved aligned DNA sequence file in Genbank format
Example of an interleaved aligned DNA sequence file in Clustal format
For more information on DNA sequence file formats try http://emboss.sourceforge.net/docs/themes/SequenceFormats.html
When I find the time I'm going to have a page that's just file extensions, file descriptions and links to converters. BioEdit is an excellent converter although Windows 7 users may have to run the 16 bit application readseq in a virtual XP window Seqverter is another good file converter.
